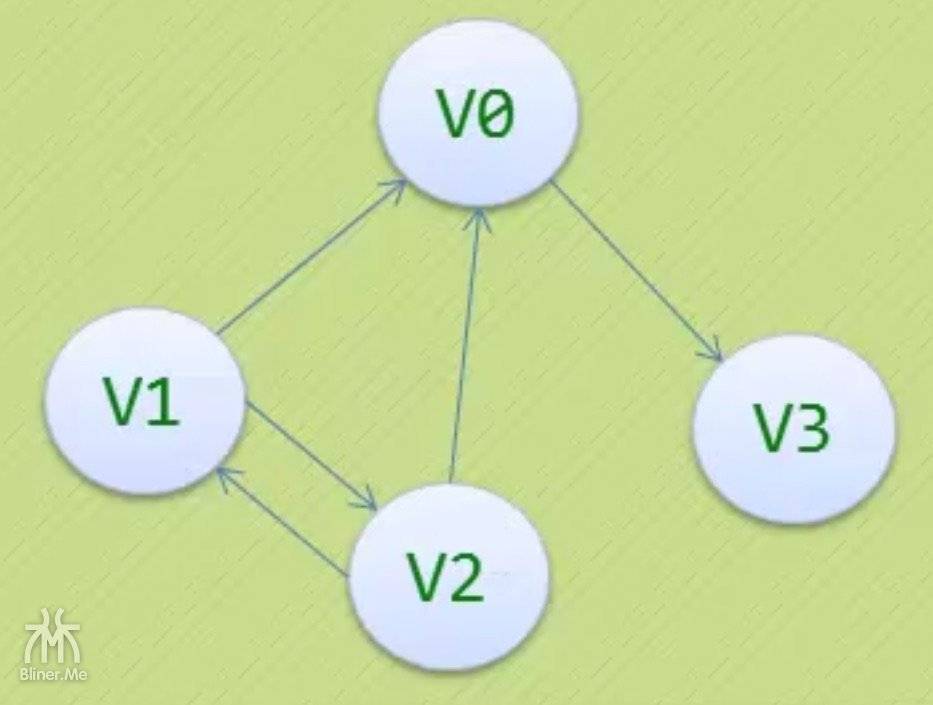
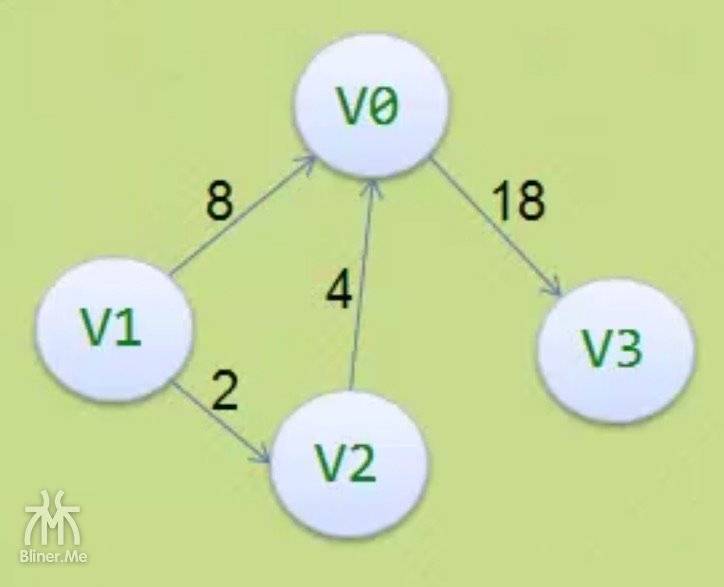
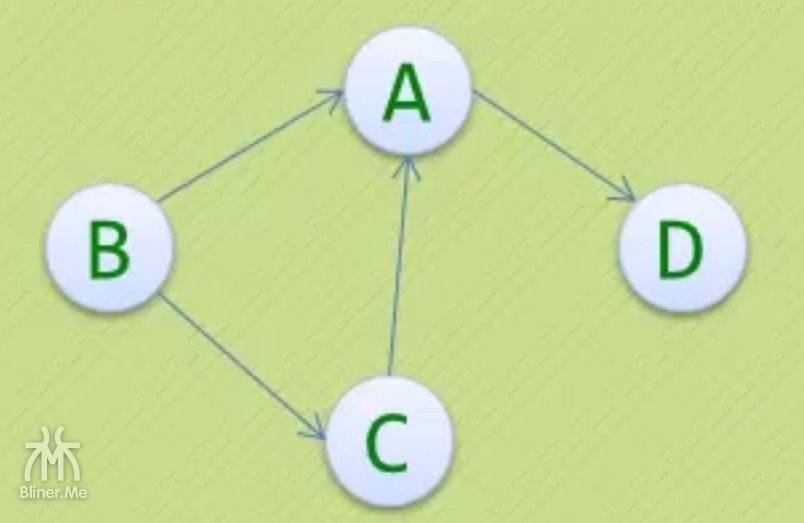
引入
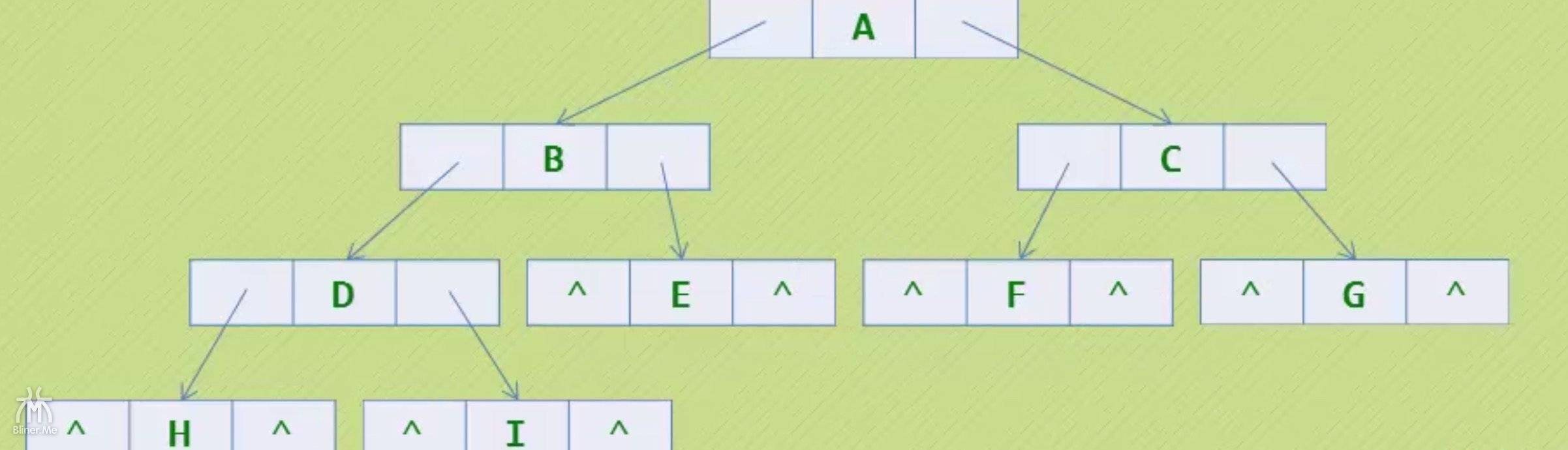
我们知道如何构建一个图的数据结构,那么现在,我们看看如何根据一棵图的图形,创建一张图到内存中去。
创建数据结构
1 |
|
数据结构中
- 记录顶点的数量和边的数量,等下用作循环判断条件
- 记录图得类型,等下用于写入矩阵
获取数据
1 | void create_MG(MGraph *MG) |
我们一部分一部分的讲
- 先输入1或0判断图类型,然后存到结构体中
- 然后输入顶点数和边树,方便下面判断循环次数
- 接着根据顶点数,接收每个顶点得值
- 所有数据获取完毕
初始化矩阵
1 | //初始化邻接矩阵,双层循环将二维数组都填充为0 |
这里我们先把矩阵创建出来
- 判断条件就是顶点的个数,有多少顶点创建多大的矩阵
- 矩阵中默认的值为0
在矩阵中定位
1 | //定位 |
这个定位的函数,主要是
- 将用户输入的值,在一维数组中找到它的位置
- 然后将这个位置返回
- 我们就能通过这个位置在矩阵中定位到它了
处理边的信息
1 | //输入边的信息,建立邻接矩阵,有多少边执行多少次 |
有多少个顶点就循环多少次
- 接收到构成边的两个顶点
- 然后利用上面的定位函数,返回在一维数组中的位置
- 接着判断图得类型
- 无向图,那么矩阵对称,则在对称位置同时赋值 1
- 有向图,矩阵不对称,所以只在对应位置赋值 1
总代码
1 |
|
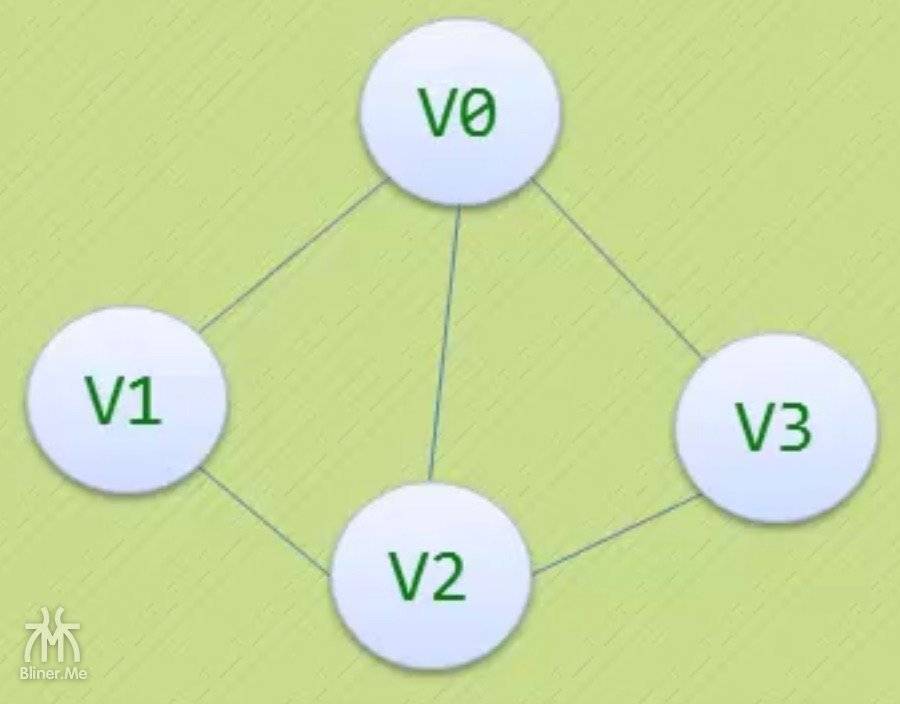
| V0 | V1 | v2 | v3 | |
|---|---|---|---|---|
| V0 | 0 | 1 | 1 | 1 |
| V1 | 1 | 0 | 1 | 0 |
| V2 | 1 | 1 | 0 | 1 |
| V3 | 1 | 0 | 1 | 0 |
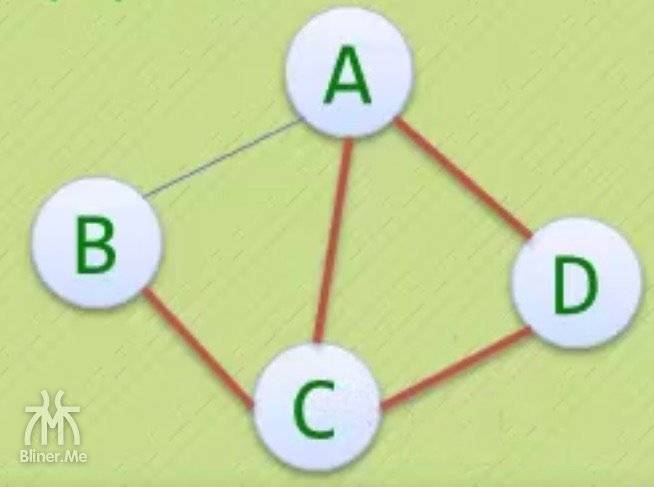
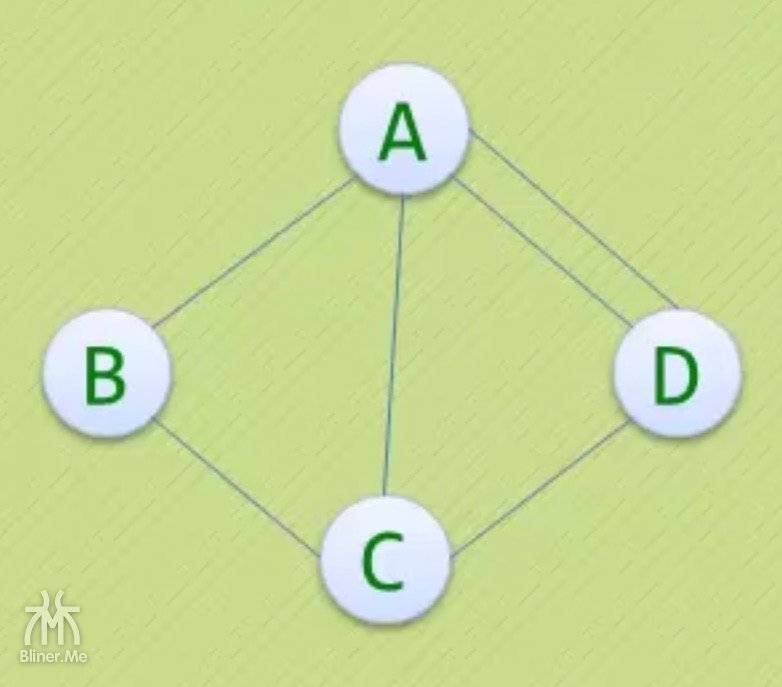
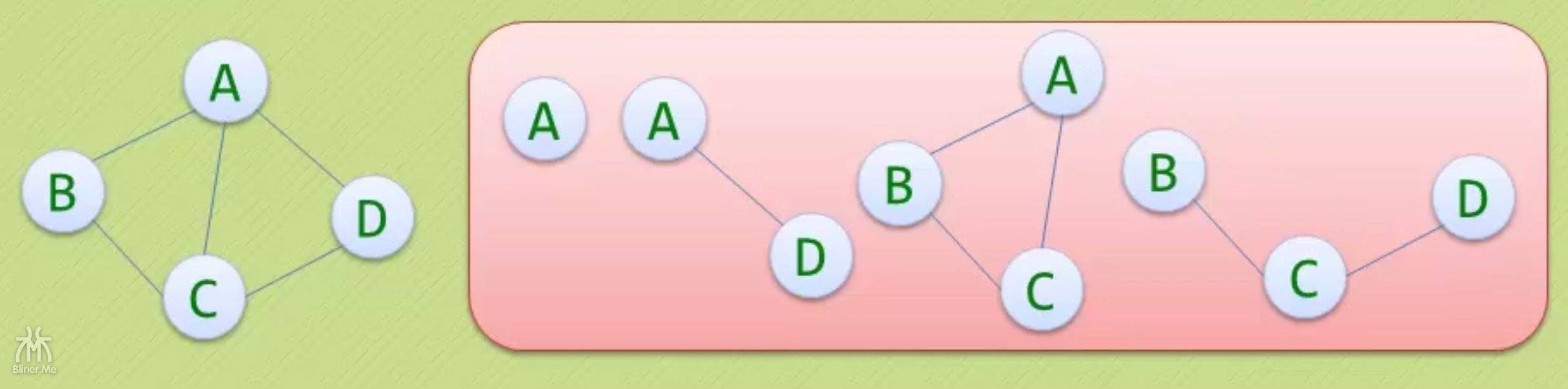
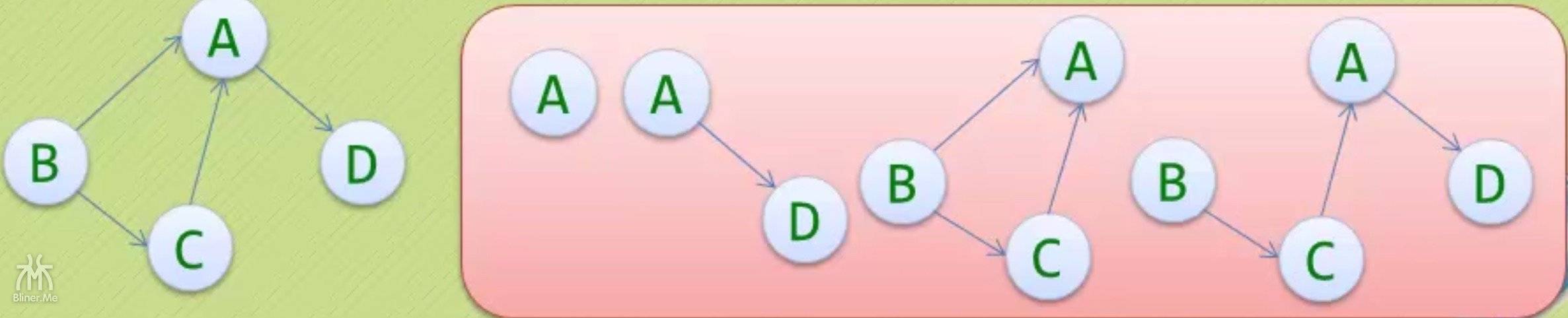
我们将上面的图输入程序,我们用 a、b、c、d 代替v1、v2、v3、v4
运行结果
请输入图的类型,有向图输入1,无向图输入0:0
图有几个顶点:4
图有几条边:5
请输入第1个结点的值:a
请输入第2个结点的值:b
请输入第3个结点的值:c
请输入第4个结点的值:d
请输第1个边的信息:a b
请输第2个边的信息:b c
请输第3个边的信息:c d
请输第4个边的信息:d a请输第5个边的信息:a c
图类型:无向图
图中的顶点有: 4 个
图中的边/弧有: 5 个
顶点的集合:a b c d
邻接矩阵:
a 0 1 1 1
b 1 0 1 0
c 1 1 0 1
d 1 0 1 0
运行结果同矩阵相同,成功!
尾巴
这是我的个人学习笔记,主要是应付考研复习使用,充斥着一些吐槽和个人观点,并不严谨,欢迎大家参考、指正。
]]>