引入
如果学习过数据结构,就会知道,链表是一种常见的重要的数据结构。它是动态的进行存储分配的一种结构。
在前面的学习中,我们知道,用数组存放数据时,必须线定义数组长度,也就是数组中元素的个数。
那么如果我们用来存储班级人数,有的班级100人,有的班级30人,那么为了能放下100人的数据,我们必须设计一个100个元素的数组。显然,这会浪费很多内存。
链表,就没有这种缺点,它根据需要开辟存储单元。
链表
我们先来看一个链表

- head :表示链表中的
头指针变量。它存放一个地址,该地址指向一个元素。链表中的每一个元素,称为结点; - 节点 :表示链表中的每一个元素,每个结点都应该包含两个部分:
1.是用户所需要用的实际数据
2.是下一个结点的地址。
上面的图中,head 是头指针,指向第1个元素
第1个元素指向第2个元素,以此类推
直到最后一个元素,该元素不再指向其它元素,它称为表尾
表尾的地址部分存放的地址为:NULL
链表到此结束
- 我们看到,链表中的各个元素的内存中的地址可以是不连续的。
- 我们要找到某个元素,必须找到上一个元素,根据它提供的下一个元素地址,才能找到这个元素。
- 所以,不提供头指针,我们整个链表都无法访问。
简单来就是,一个数据结构结构中,出了本身要存储的数据,还有一个指针类型的数据,用来存储着下一个结点的地址。
试试看
我们使用前面学过的结构体的知识和刚刚学习的链表的知识,来设计一个链表。
1 | struct Student{ |
当然,上面指针类型的成员,即可以指向自己所在的结构体的数据,也可以指向其他结构体类型的数据。
注意,上面只是声明了结构体类型,并没有分配存储空间,只有定义了才会分配存储空间。
建立简单的静态链表
我们根据下面的图示,来设计一个简单链表,输出各个结点的数据。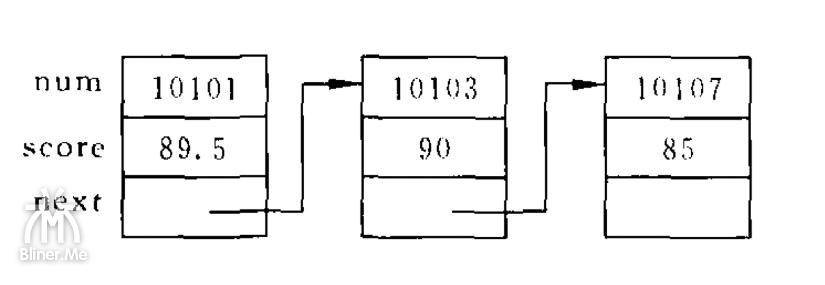
1 |
|
我们设计了一个 p 指针,先使用 p 指向 a 结点,输出 a 之后,移动指针,但不是向后或者向前,而是移动到 a 存储的下一个数据的地址。直到下一个地址是 NULL 为止。
我们称上面的链表为静态链表:
- 上面的结点都是我们定义的,不是临时开辟的。
- 在用完之后不能释放。
尾巴
这是我的个人学习笔记,主要是应付考研复习使用,充斥着一些吐槽和个人观点,并不严谨,欢迎大家参考、指正。

